谈谈对分布式系统的一些思考
文章目录
说明
本文限定在分布式系统不考虑拜占庭问题。即所有节点都是可信的。
定义
分布式系统是多个节点协作完全一个共同的业务。
重要性
分布式理论的重要性毋庸置疑,一句话总结:没有分布式理论,就没有现在互联网与云计算。在分布式系统实践过程中离不开分布式系统理论指导,对其重要性打个比方:分布式系统理论是分布式系统实践过程中地图与导航。
分布式主要解决问题
分布式主要解决以下几个问题:
- 解决SPOF问题,满足高可用性需求
- 解决Scale out问题,满足扩展性需求
- 解决数据分布问题,满足业务的需求
分布式是解决方案也是问题
一般情况,人们为了解决一个问题,往往会引入一个新的问题。试想如下: 由于SPOF存在,再加入一个节点作为备份。这样确实提高了系统高可用性,但是有以下新问题:
- 如何检测节点状态?如何快速检测节点状态?
- 如果检测主节点失败,备节点如何进行切换?
- 主备节点如何同步数据?
- 网络分化出现双主,如何避免与处理?
思考模型
对于分布式系统理论,分为以下几个子问题:
- 在什么环境下?
- 有哪些节点参与?
- 通过什么样的共识算法?
- 使什么业务?
- 达成什么样的容错要求?
总结一句话:在什么环境下,有哪些节点参与,通过什么样的共识算法,使什么业务达成什么样的容错要求。
下面就这五个问题展开说明。
环境
分布式系统环境特点如下:
- 从网络同步模型上分为同步网络,异步网络,半同步网络三种
- 系统异常是常态
- 网络传输是不可靠的
- 并发
- 缺少全局时钟
网络模型
同步网络是指网络带宽与延迟都是可以保证的。实际上现在IP网络都不属于这种,满足这种的网络是ATM网络(注意不是我们常见的提款机ATM)。
异步网络则是指网络带宽与延迟都不确定,在异步网络发送的报文会丢失。我们正在使用主的IP网络属于这种。
部分同步网络处于这两者中间。
异常
机器异常通常有以下几种情况:
- 电源
- 机器元器件故障如内存,硬盘
- 操作系统故障
- 软件故障与程序bug
- 资源耗尽,如内存,CPU,硬盘空间,网络带宽等
网络传输不可靠
网络传输不可靠主要体现以下几个方面:
- 丢包,传输成功不确定性
- 延时,延时时间不确定性
- 重传与报文重复
- 乱序
并发
如同操作系统中多线程并发,分布式系统多节点在并发。但是分布式系统的并不能像多线程上通过操作系统的锁机制来处理并发,在分布式系统实现一个锁比操作系统上难度大多了。
缺少全局时钟
一个人有一只表时,可以知道现在是几点钟,而当他同时拥有两只时却无法确定。分布式系统不同节点很难有相同的时钟。
节点
节点数量
节点数量,在实践过程中,至少两个,常见三个节点,部分情况五个节点。
节点角色
以raft为例可以分leader,follower,candidate等角色。
节点可信
全是可信节点,不存在作恶节点。
节点准入
主要方式是通过配置管理指定节点。
节点配置
虽然节点之间机器配置,网络带宽,地理位置都会存在一定程度上的差异,但是可以控制。
共识算法
共识算法是核心。最常见共识算法如下:
- Paxos
- Raft
- Zab
- Primary-secondary
- Quorum
属性
一个科学共识算法必须同时满足以下四个属性:
- Agreement
- Validity
- Integrity
- Termination
这四个属性从四个方面规范共识算法的要求,也为我们提供分析共识算法四个不同的视角。
Agreement
Every correct process must agree on the same value.
这是实现一致性必须要做到的要求:每个节点必须达成一致。
Raft通过以下几点实现Agreement,具体如下:
- 整个系统保证最多只有一个leader
- 同步流只有一个方向:从leader到follower
- 节点crash后从leader同步数据
- 重新选主之后的冲突解决机制,如选主过程选择拥有最新数据的candidate为新主
Validity
If all the correct processes proposed the same value v, then any correct process must decide v.
Validity是为了防止这种情况的出现:一些节点无论提议什么值,本节点一直提交NULL。
Raft通过以下几点实现Validity,具体如下:
- 整个系统保证最多只有一个leader
- 同步流只有一个方向:从leader到follower
- 节点crash后从leader同步数据
Integrity
No Node decides twice.
保证共识得到一致性不可逆,不可被修改。那么在这成共识过程中有许多操作需要进行限制。以Raft为例,其通过以下几点实现Integrity,具体如下:
- 节点都是可信的,节点不作恶
- 节点自我约束,只会commit一次
- 节点选leader过程中一次只能投一个candidate
- leader节点从不会覆盖自身本地日志中已经存在的条目
- 在存在两个leader情况下(一个真leader一个假leader),能够根据item和index识别真假leader
Termination
Eventually, every correct process decides some value.
Termination是一个liveness属性,可以理解对应CAP定理中可用性(Availability)。 对应Raft体现如下:
- 多数派保证能够容忍一定的节点crash
- leader与follower通过心跳包实现检测
- 检测到leader crash,follower发起新一轮选主,保证系统正常运行
- 正常工作的时候,由itemId及indexId来保证一个周期的结束 这样就基本保证多数节点正常工作,整个系统能够保证有且只有一个leader(选主期间除外),另一种表达是保证系统最多只有一个leader。
(PS:建议可以读一下raft论文,读完一定会有新的理解。)
业务
分布式业务这里列举如下:
- 分布式存储,如GFS
- 分布式计算,如MapReduce
- 分布式锁,如Chobby
- 分布式数据库,如BigTable,Spanner
- 分布式ML,如TensorFlow分布式
- 分布式MQ,如Kafka
- 分布式负载均衡,如Daglev
- 分布式缓存,如分布式redis, Memcached
容错要求
对于分布式系统,其容错要求对应是CAP定理。在实际应用过程选择容错性要求根据业务来决定。
CAP定理
CAP定理指出,分布式系统不可能同时满足以下三个条件:一致性(Consistency)、可用性(Availability)和分区容错(Partition tolerance)。
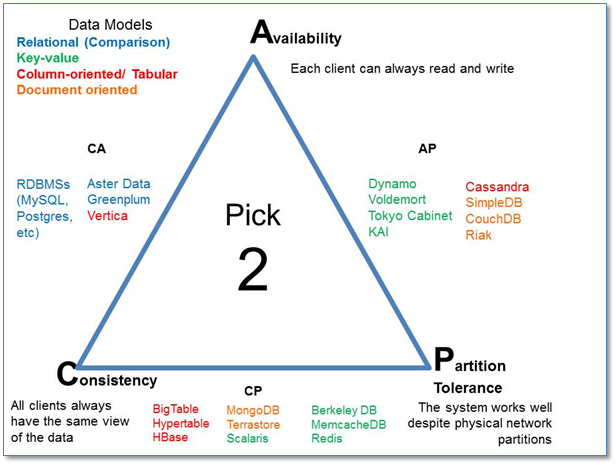
CAP里面三个选项是不同角度的容错性。
一致性
多节点加上网络的不可靠性,这样多节点的不一致状态是不可避免的。如同TCP协议,解决了网络传输不可靠性,分布式共识算法是达成一致性的方法。
一致性分为以下几种类型(来自百度的《分布式系统原理介绍》):
强一致性(strong consistency):任何时刻任何用户或节点都可以读到最近一次成功更新的副本数据。强一致性是程度最高的一致性要求,也是实践中最难以实现的一致性。
单调一致性(monotonic consistency):任何时刻,任何用户一旦读到某个数据在某次更新后的值,这个用户不会再读到比这个值更旧的值。单调一致性是弱于强一致性却非常实用的一种一致性级别。因为通常来说,用户只关心从己方视角观察到的一致性,而不会关注其他用户的一致性情况。
会话一致性(session consistency):任何用户在某一次会话内一旦读到某个数据在某次更新后的值,这个用户在这次会话过程中不会再读到比这个值更旧的值。会话一致性通过引入会话的概念,在单调一致性的基础上进一步放松约束,会话一致性只保证单个用户单次会话内数据的单调修改,对于不同用户间的一致性和同一用户不同会话间的一致性没有保障。实践中有许多机制正好对应会话的概念,例如php中的session概念。可以将数据版本号等信息保存在session中,读取数据时验证副本的版本号,只读取版本号大于等于session中版本号的副本,从而实现会话一致性。
最终一致性(eventual consistency):最终一致性要求一旦更新成功,各个副本上的数据最终将达到完全一致的状态,但达到完全一致状态所需要的时间不能保障。对于最终一致性系统而言,一个用户只要始终读取某一个副本的数据,则可以实现类似单调一致性的效果,但一旦用户更换读取的副本,则无法保障任何一致性。
弱一致性(week consistency):一旦某个更新成功,用户无法在一个确定时间内读到这次更新的值,且即使在某个副本上读到了新的值,也不能保证在其他副本上可以读到新的值。弱一致性系统一般很难在实际中使用,使用弱一致性系统需要应用方做更多的工作从而使得系统可用。
为什么一致性很重要?借用Jakob Nielsen的一句话:
Consistency is one of the most powerful usability principles: when things always behave the same, users don’t have to worry about what will happen.
可用性
可用性指服务正常可用的概率。一般用数据量化指标为以下几个:
- 服务正常可用的概率,如常说4个9
- MTBF(平均故障间隔时间)
- MTTR(平均故障恢复时间)
分区容错性
分区容错性是指系统在网络分化的情况下仍然能正常对外提供服务。
应用
遵守以不变应万变的原则,在一般工程应用过程中,先确定不变,以etcd为例:
- 在异步网络环境,机器存在一定故障
- 一般3个节点,分布在同两个IDC机房
- 提供分布式KV服务
- 容错性方面从CAP中取CA两项
确定这些之后,我们可以选择合适的共识算法及其实现。
后记
将分布式系统分解五个小问题,除了共识是一个难点,其他四个问题都容易理解,这样有利于我们解决问题外围,有一个清楚的背景知识和前期的准备,有利于理解与学习共识算法。作为一个思考框架,围绕框架不断地完善,如深入分析分布式业务和提高分布式系统的性能。
个人能力有限,有什么不足与错误,欢迎指正。
参考
- Consensus
- raft动画演示
- raft论文
- 寻找一种易于理解的一致性算法(扩展版)
- Raft Distributed Consensus Overview
- 你矜持,你活该
- Distributed systemsfor fun and profit
- 分布式系统相关挑战
- My Distributed Systems Seminar’s reading list for Spring 2020
- A Thorough Introduction to Distributed Systems
欢迎关注
欢迎关注微信公众帐号:沉风网事(savewind)

文章作者 沉风网事
上次更新 2018-12-11